
Blog 🔭

We’re excited to introduce a new enhancement to Dcipher Analytics’ AI-powered Research Matrix: the ability to generate executive summaries for both rows and columns. This update makes it even easier to extract key insights from complex datasets - whether

We’re excited to introduce new analysis modes in Dcipher Analytics Radar, enhancing its capabilities for trend detection, horizon scanning, and arena analysis. What started as a trend radar - a tool for identifying emerging trends across large volumes of

We’re excited to introduce Research Agents - a powerful new feature in Dcipher Analytics that transforms web-based research. Traditional methods, whether manual or automated, have significant limitations. Research Agents overcome these challenges by combi
How about getting a shortcut to the sites that all the buzz is about? Dcipher Analytics’ automated AI workflow scans social media posts within your specified domains for links to external sites—and serves you the 100 links that have been shared the most.
Are you ever curious about some online subculture, niche discussion, or even conspiracy theory—but don’t feel like reading through endless social media threads to get to know it? In this blog post, we explore how a Dcipher Research Bot can be used to lear

Have you tried training Dcipher Research Bots on news yet? They are the perfect solution when you need to find answers about what is going on.

In this blog post, we take a look at how we can use a content landscaping workflow to pick up insights about Generation Z in Japan from Japanese news articles—without even knowing Japanese.

Have you seen our workflow for daily social media updates? Using this, you get daily updates with the top 15 trending topics from social media in your specific area of interest directly to your Slack or Microsoft Teams channel.

In this blog post, we take a look at how Dcipher Research Bots can be used to quickly find information hidden in long and complex texts, using the EU Artificial Intelligence Act as an example.

Do you wish you could get ready-made summaries of what is written within your topics of interest in global news media or in a set of reports? Dcipher Analytics offers workflows tailored exactly for that—letting you automate your desk research and get more

A Dcipher Research Bot is a life saver whenever you have questions about what is reported and discussed in news or social media. In this blog post, we train a bot that can tell us about the news reporting from the U.S. primary elections.

What does today’s world believe will happen in year 2030? In this blog post we use Dcipher’s Insight Booster Toolkit for a foresight exercise to map out what news media around the world are talking about when they mention that year.

Artificial Intelligence has dramatically redefined the insight generation landscape, transforming the cumbersome process of gathering, processing, and analyzing massive amounts of textual data, be it news reporting, social media, or reports, into a more s
Are you using our content landscaping workflows? Content landscaping is a highly effective method for mapping and exploring themes from texts in a visual way. We recommend using them whenever you get an overview of a large set of text data.
Designed to simplify content accessibility and optimize user interaction, our Knowledge Bot is more than just a regular chatbot. It's an automated analyst, a digital librarian, and a 24/7 customer representative, all combined into a powerful tool nested r

Let us introduce you to our new research bots! They can be used as your personal desk research assistant, to enhance the access to information inside your organization, and much more. You can even integrate our bots into your own website.
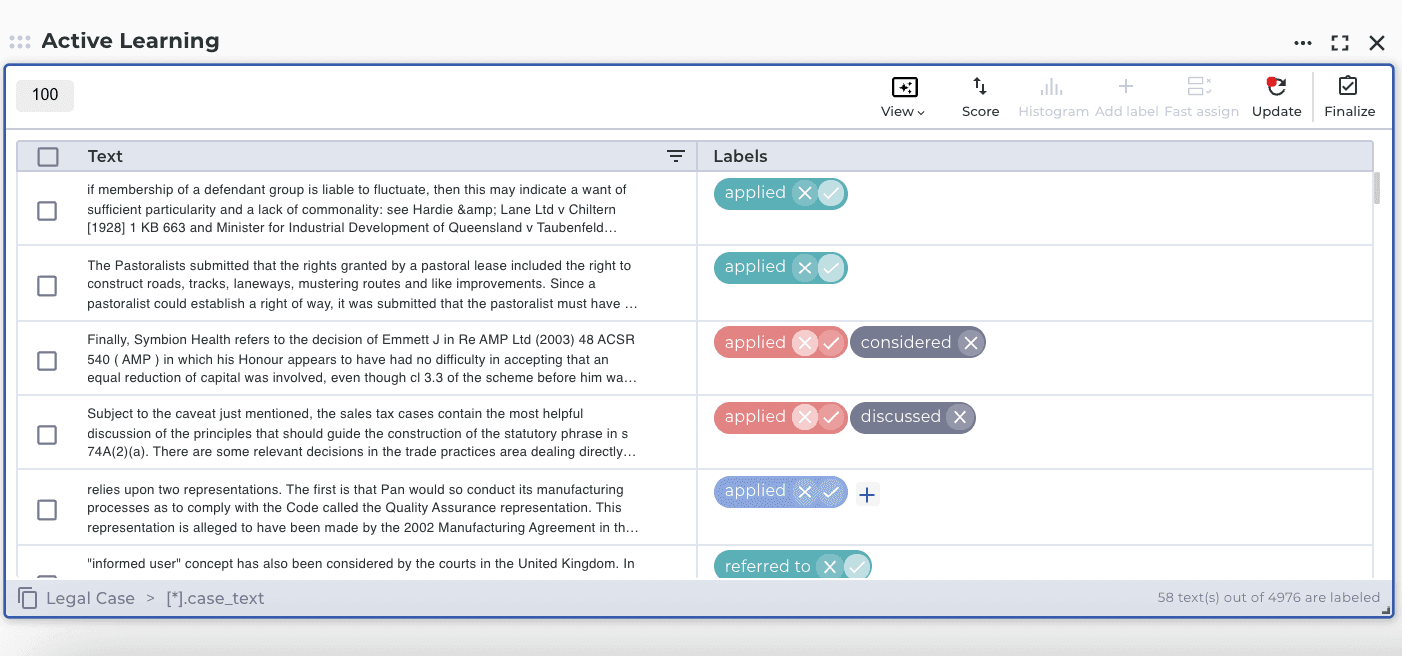
This blog post explains the usage of Active Learning workbench and training a customized ML model to classify legal cases and predict their possible outcomes in the legal context, such as "referred," "applied," "distinguished," "discussed" and "considered
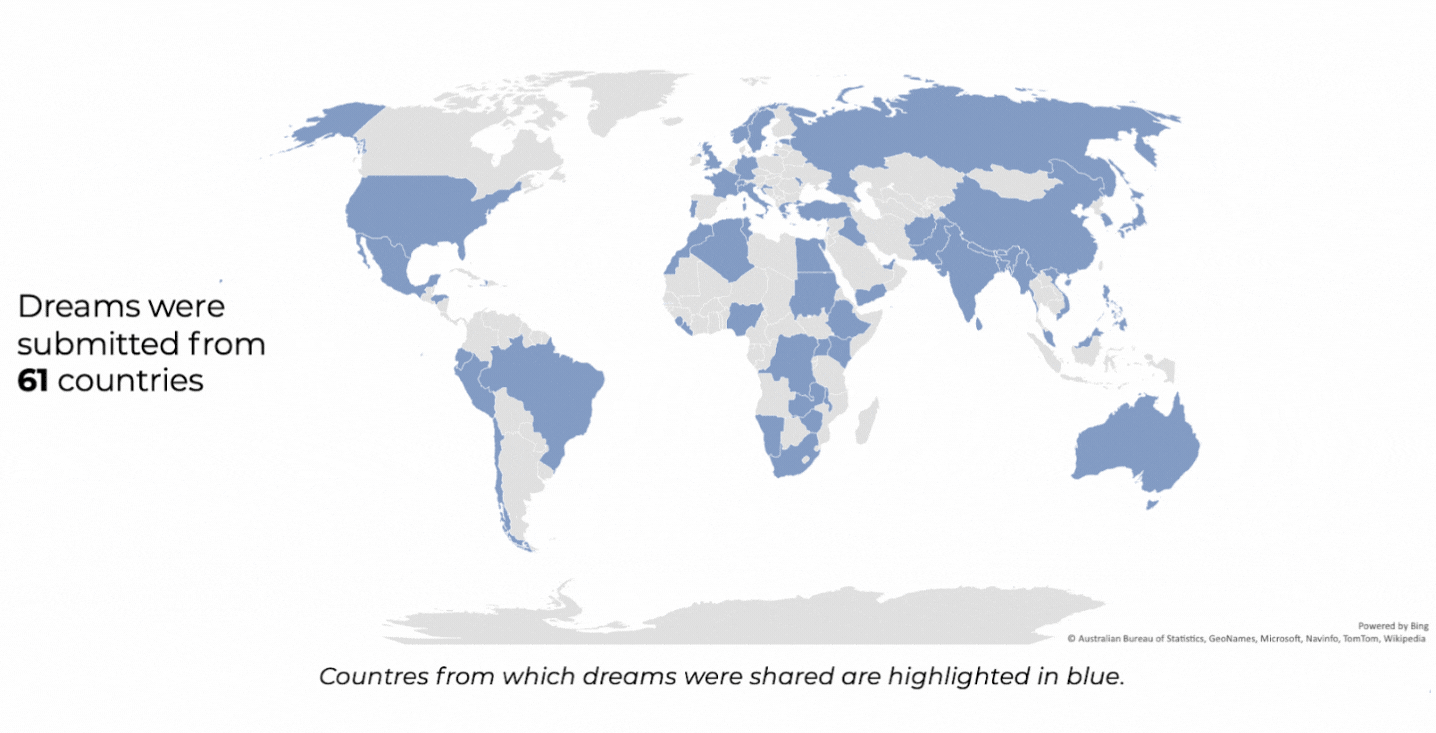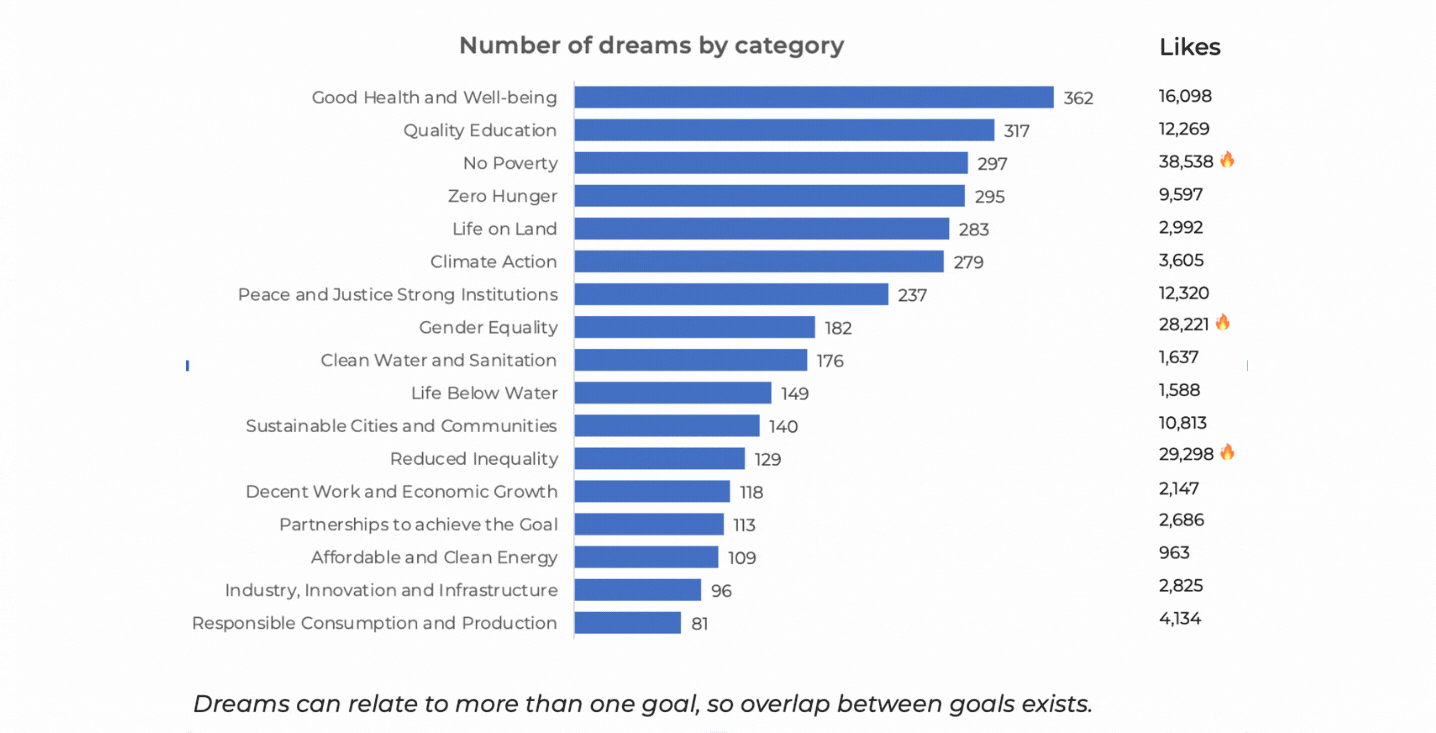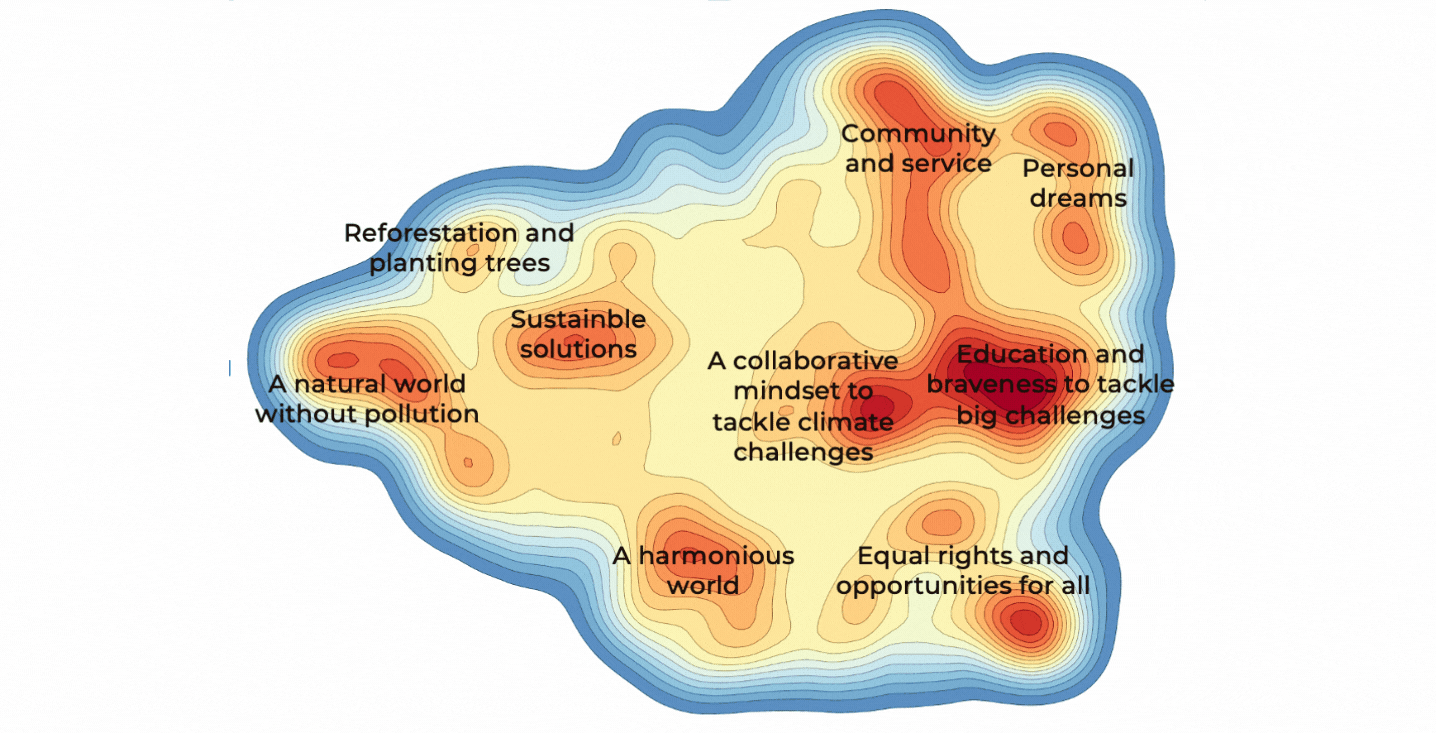
Deep dive into the dreams of people all around the world by using Natural Language Processing (NLP)
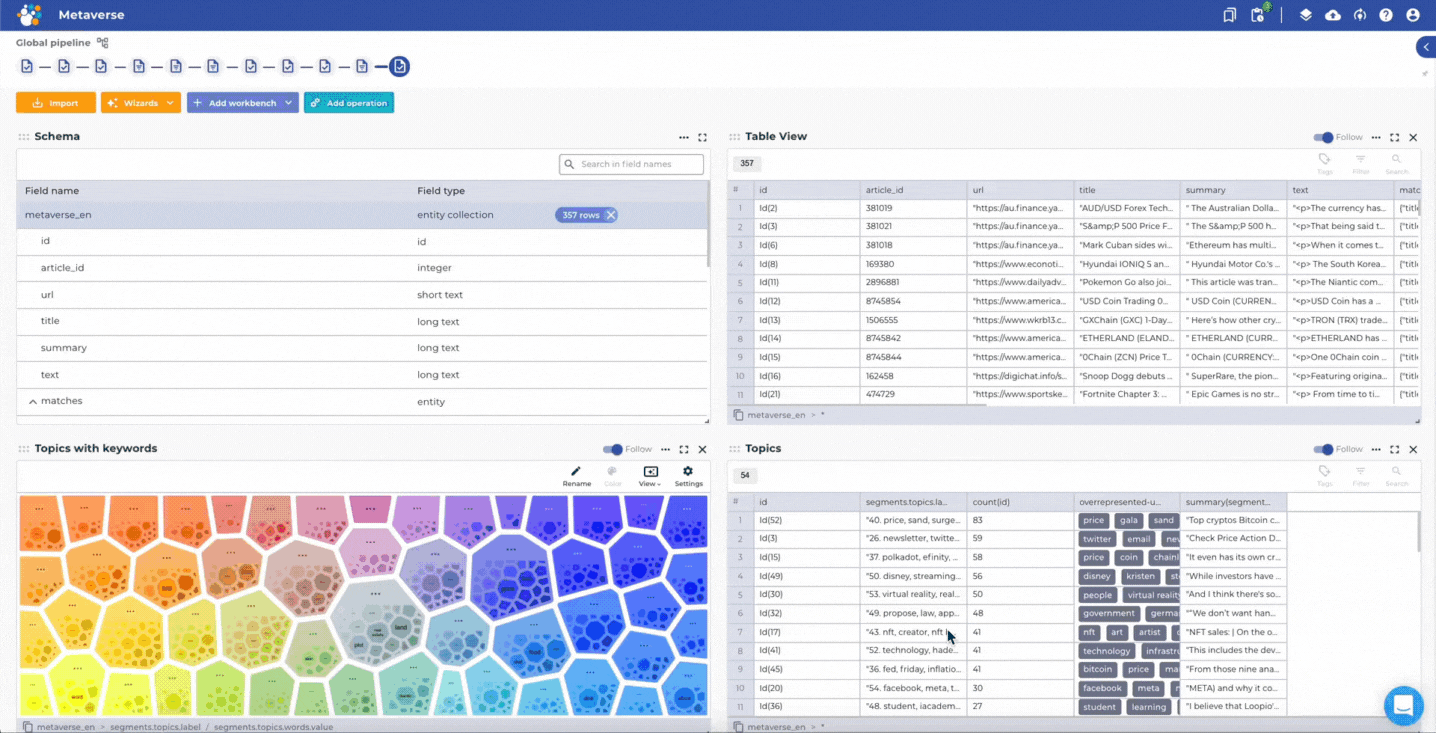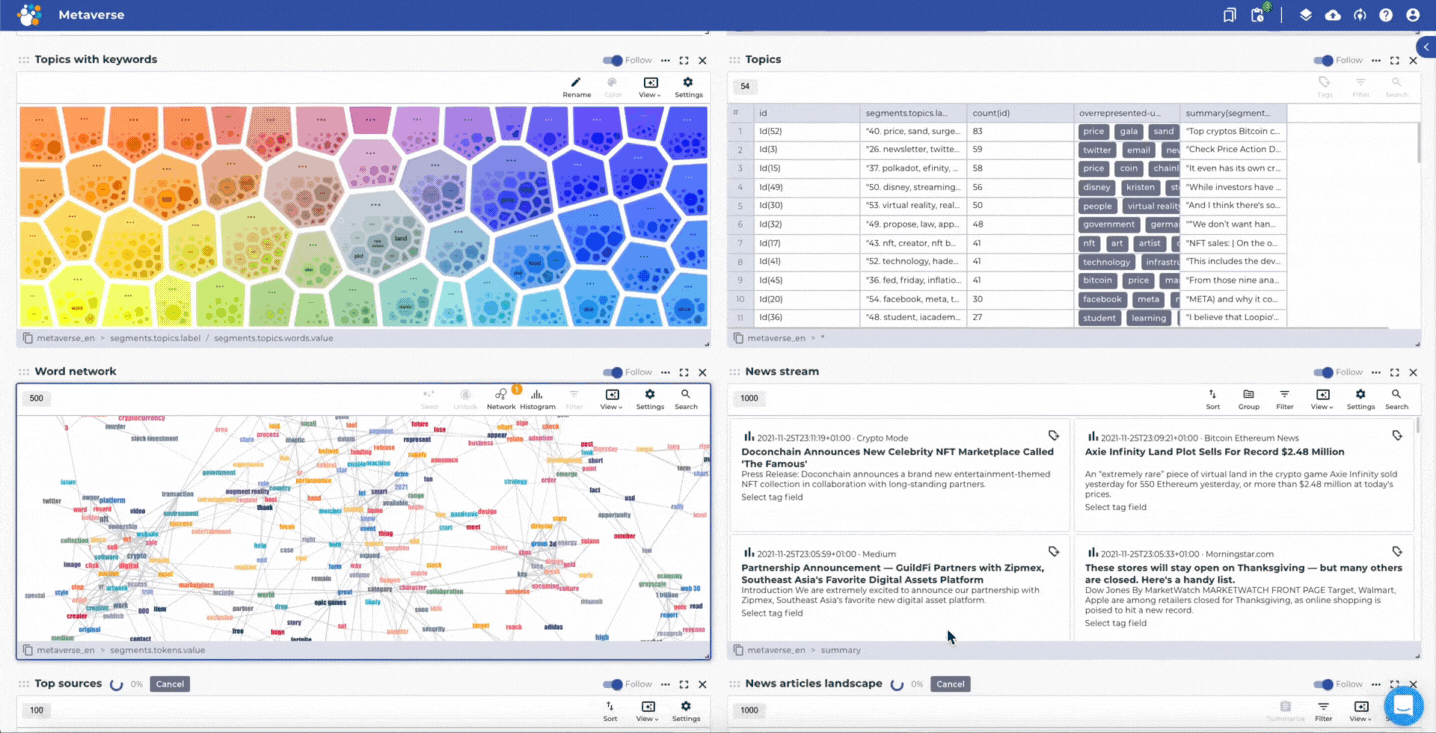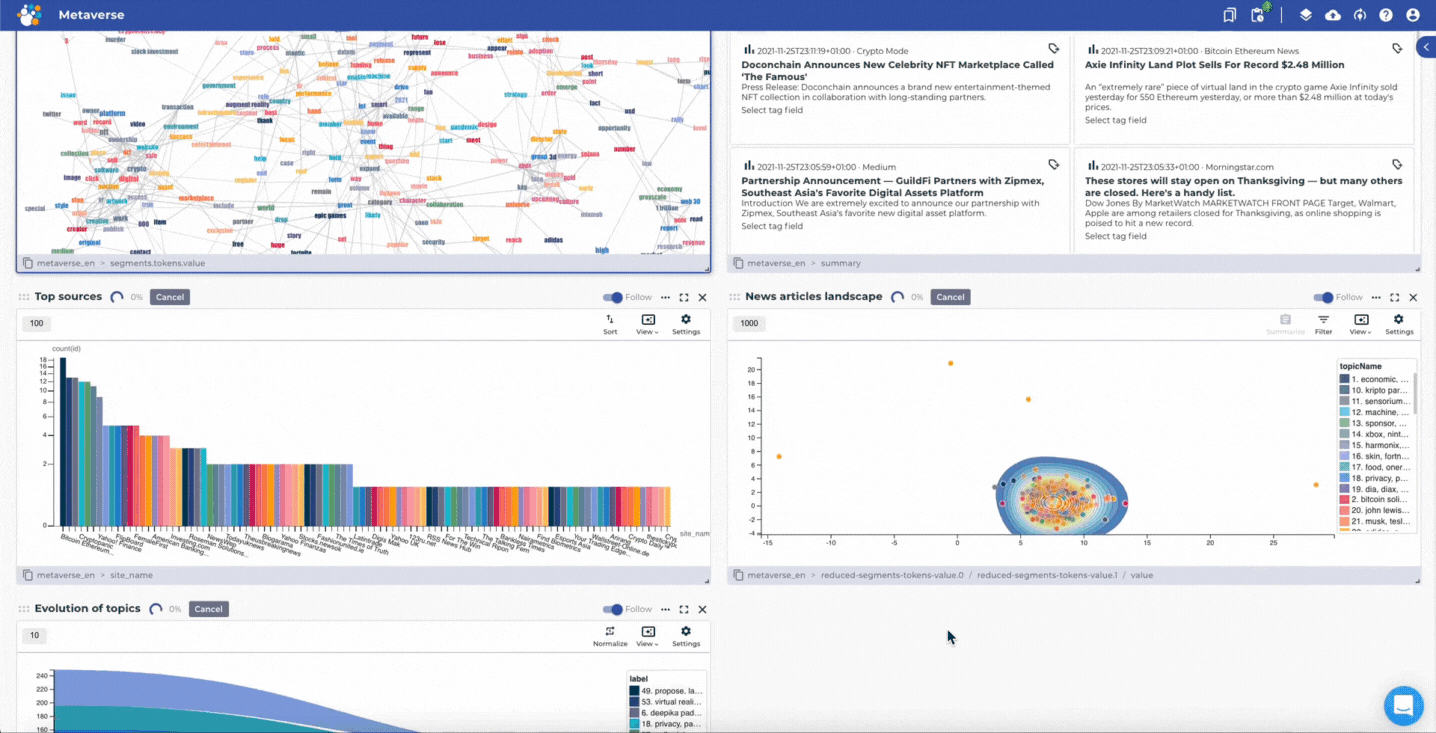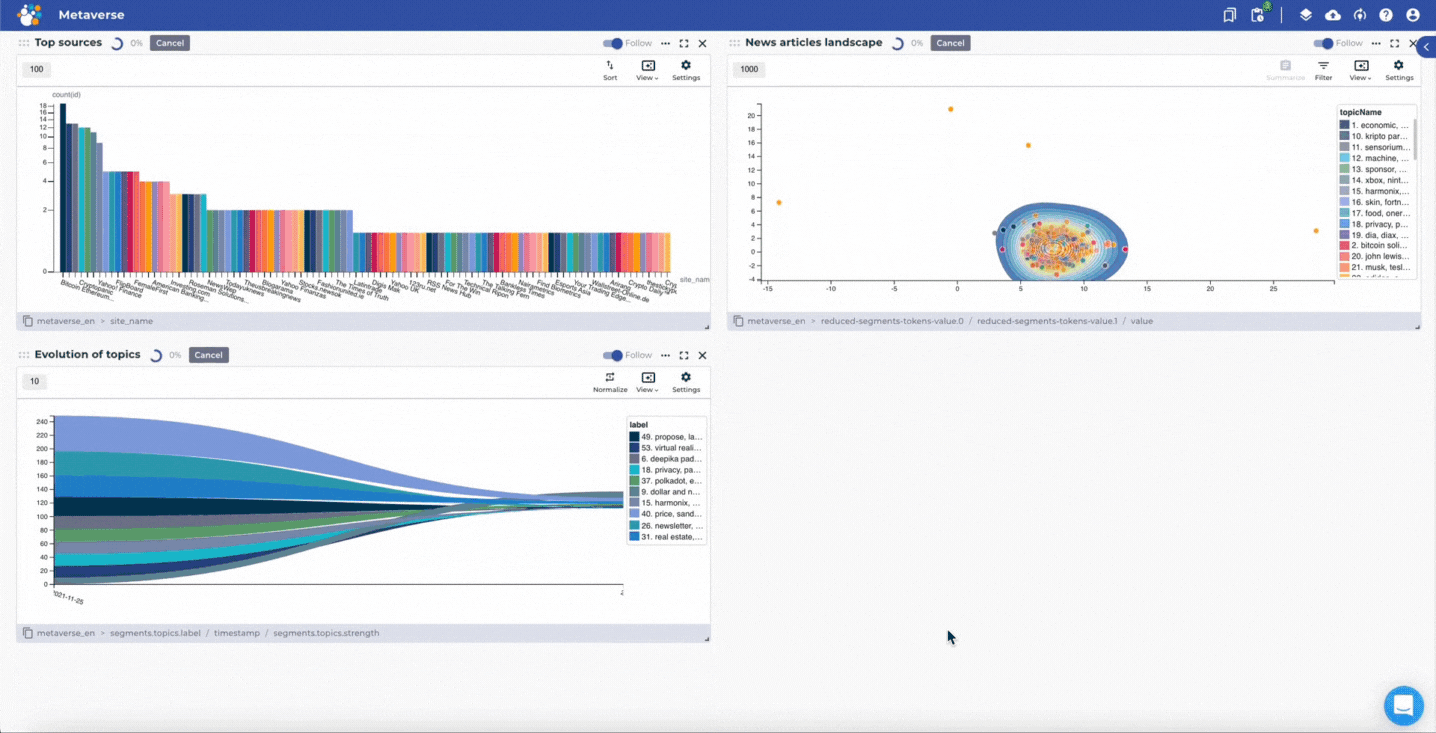
Mining and creating insights based on news articles about the Metaverse by using the news media scanning project template.
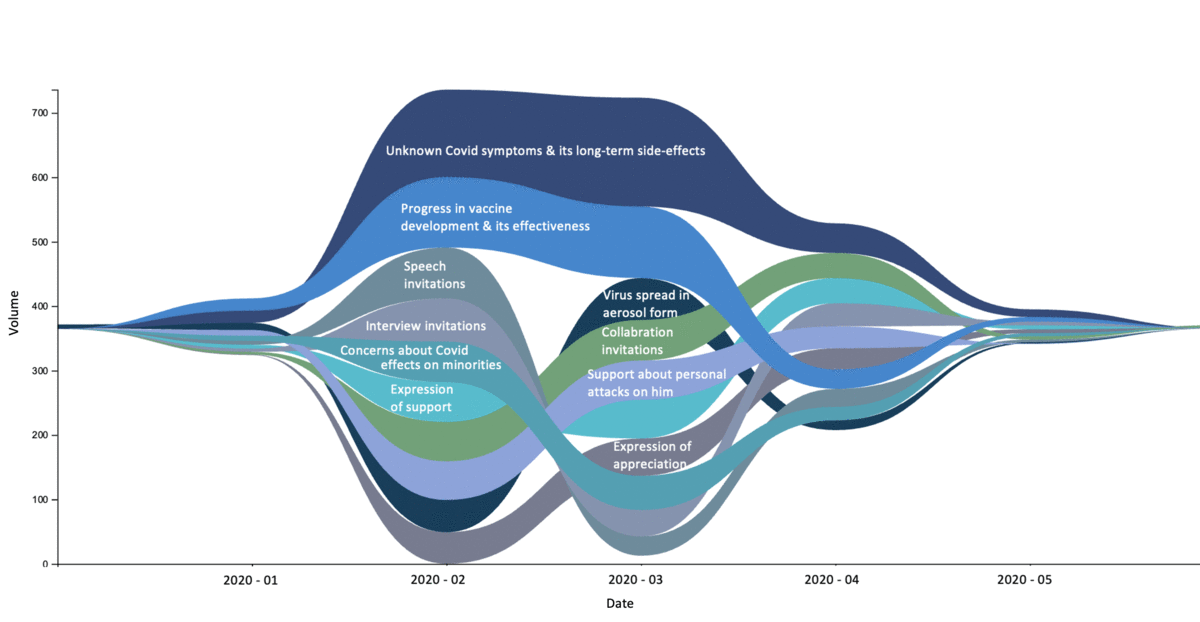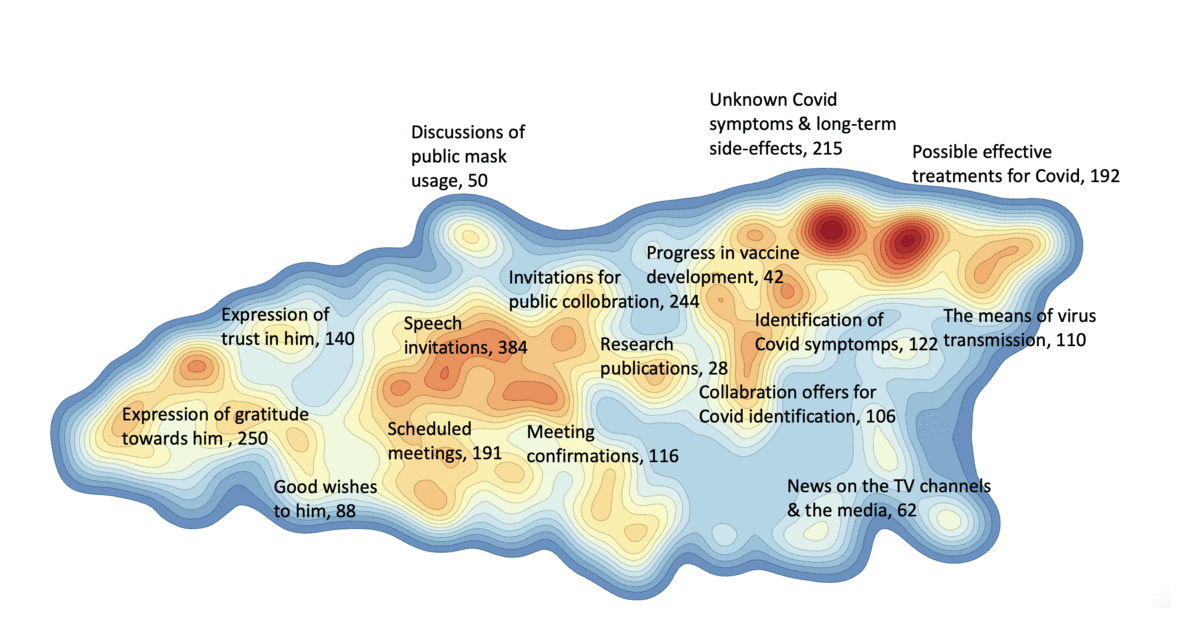
Text analysis can be used in various cases. One of the usages is analyzing emails as text data and figure out valuable insight from that.

Social media is one of the most helpful resources for data analysis. However, It can be challenging to analyze a high amount of data. In this text analysis, by using social media posts, you will discover where Americans plan to visit for this summer, in 5

Text analysis can be helpful in various aspects you cannot even think of. In this post, you find the best gift ideas for Father's Day by using social media analysis.
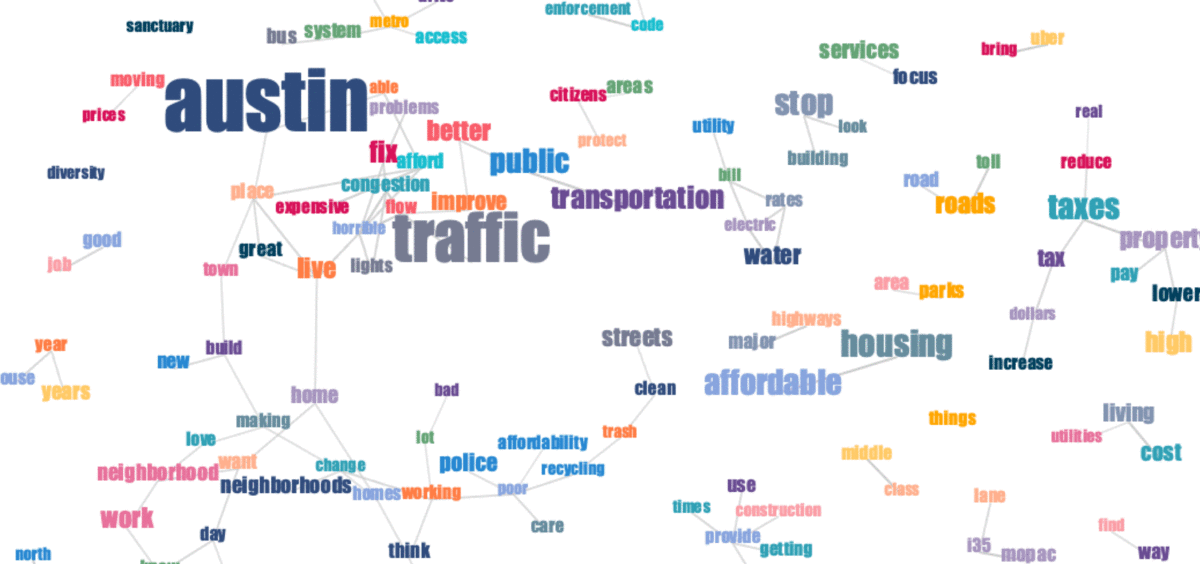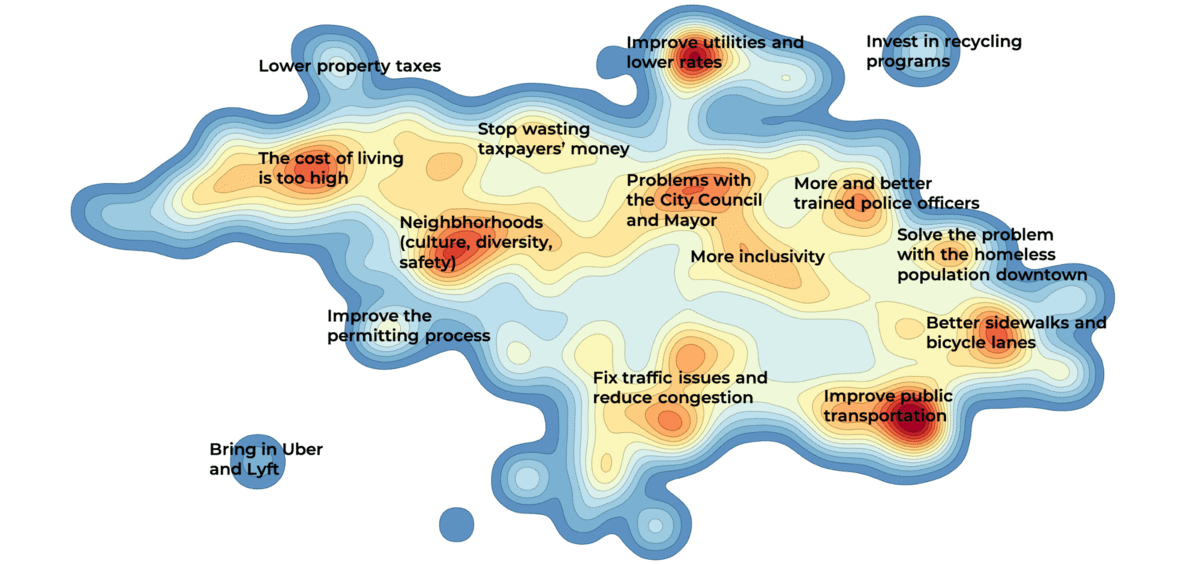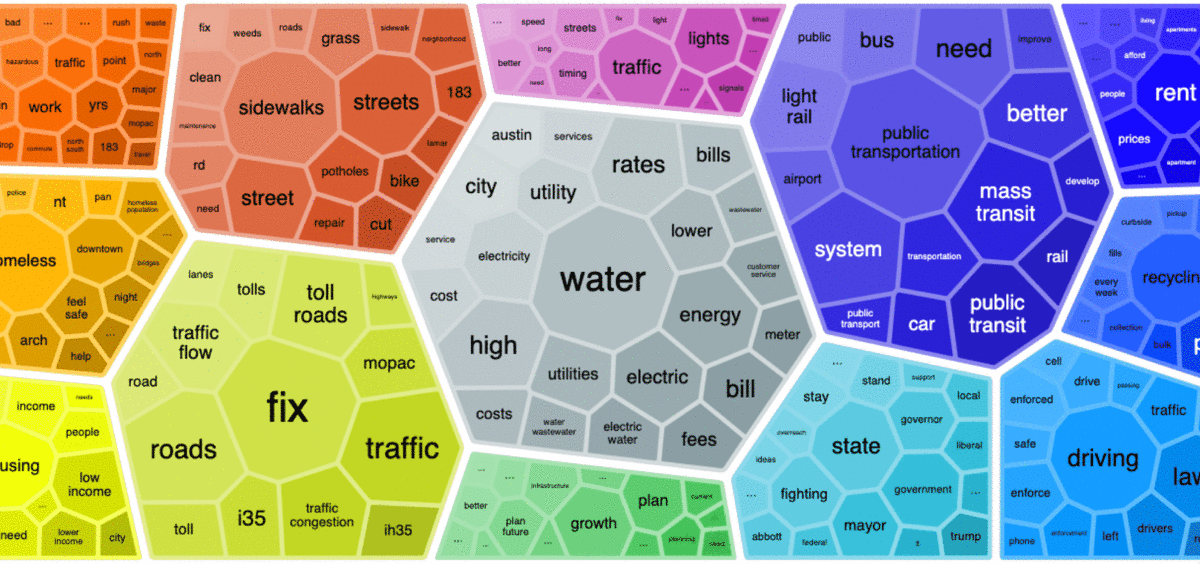
Open-ended survey questions are notoriously difficult to analyze. This post shows four easy ways of visualizing them.

Free-form text responses in surveys are a gold mine of information. This post describes how to mine it.

Social media contain open and public discussions about every conceivable topic. These discussions can provide invaluable insights into the views and narratives among consumers, influencers, and businesses. But the information is unstructured, in the form