
A step-by-step guide to AI-powered mapping of any topic: examining the discussion about Greta Thunberg in social media
In this post, we analyze the discussion about Greta Thunberg in the public social media sphere to understand who is talking and what they are saying. We identify key influencers and map the discussion.
This post can also be read as a step-by-step guide to how to analyze the discussion about any topic in Dcipher Analytics, no matter how much information there is about it. It describes a new approach that helps seeing the forest and the trees at the same time.
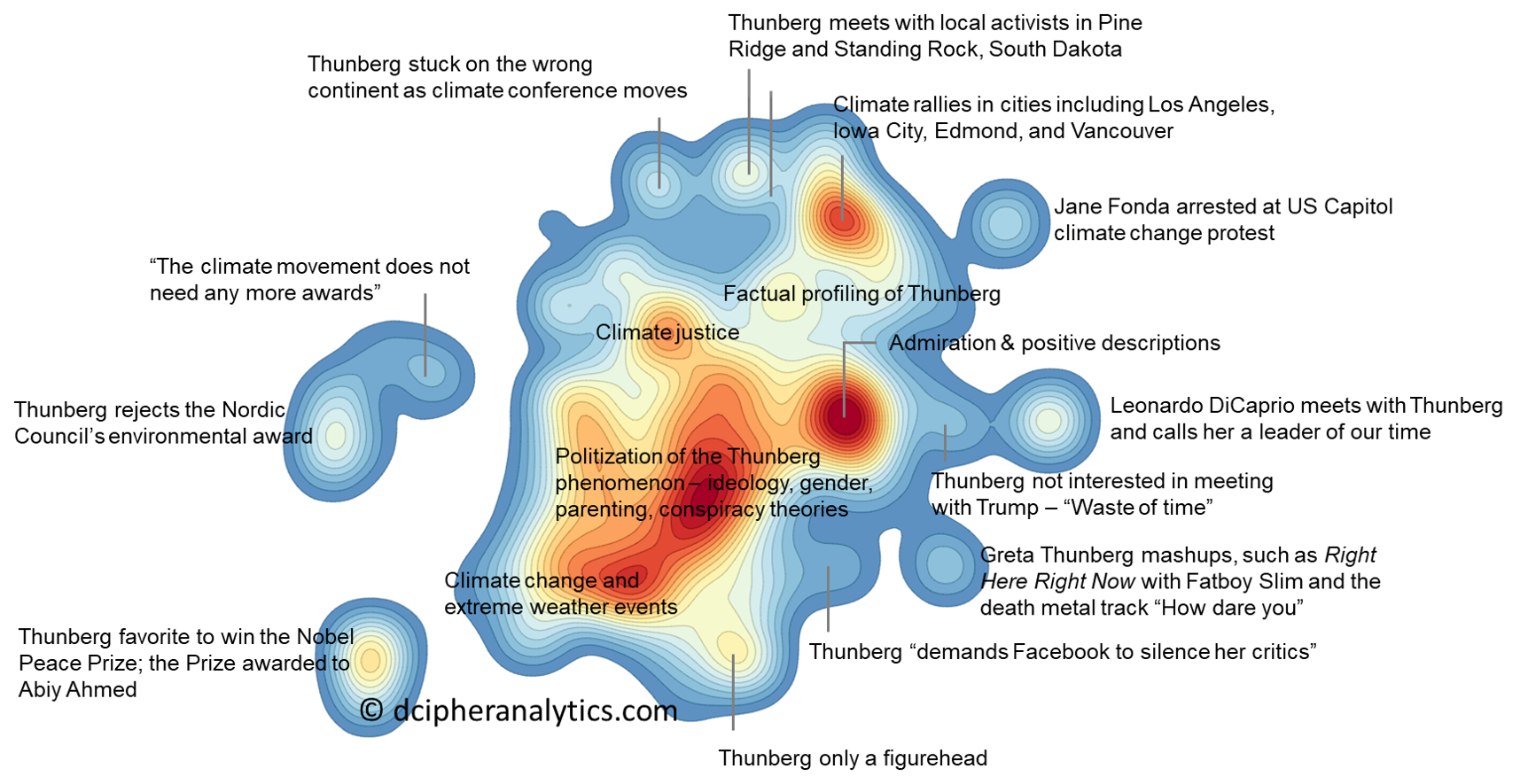
The chart below turns 20,000 paragraphs about Greta Thunberg into a map of the discussion, where similar messages have been clustered together using the latest machine learning techniques. Popular topics lead to the formation of dense regions of messages, which translate into peaks in the landscape. Navigating this landscape and interpreting the texts around each peak helped us very quickly get an overview over the discussion without actually having to read all the 20,000 paragraphs.
Step 1: Import data
Dcipher Analytics provides access to public content in a number of social media channels. Typing our keyword of interest, “Greta Thunberg”, and hitting Find posts returns the number of available posts in each source in the last month. We decide to download a subset of the data: the 31,980 public Facebook posts and 2,022 public Instagram posts published over the past month.
Step 2: Inspect the data
Now that the data has been downloaded, we want to have a look at it. The Schema view gives an overview of the different fields in the dataset. Dragging the dataset to the Show data drop zone in the Document Summary view shows the dataset as a table, which is useful to get a better understanding of it. We can right-click column headers with nested data and click Flatten to see columns one step down in the hierarchy.
To get a better overview of the data, we want aggregate certain parts of it. To understand what languages posts are written in, for example, we drag the post_language_code field to the Show as bubbles drop zone in the Bubble view. Finding that the posts are written in more than 20 languages, we decide to limit the scope to English posts (though Dcipher has functionality handle posts in different languages as well as to auto-translate them into a single language). To do this, we select the English language code, click Filter and apply a filter that includes only English posts. This leaves us with 14,553 posts.
Step 3: Prep and clean the data
Detect language and eliminate non-English posts
Inspecting the post in the Document summary view again shows us that even though most of the posts are in English, some o f them are still in other languages. To eliminate these posts, we use Dcipher’s built-in Detect language operation. Displaying the results as bubbles helps us quickly apply a filter to eliminate posts in other languages than English.
Remove duplicates
Next, we group the posts by dropping them on the Group by field drop zone in the Document Summary view. This shows us that a number of posts appear many times, one of them 53 times. We therefore run the Remove duplicates operation on our text data when sorted by date, which leaves us a single version of each post.
Clean text
Discovering that the messages contain what for the purpose of our analysis is to be considered noise, such as XML tags, hashtags, and @ tags, we use the Clean text operation to clean the messages and output the cleaned version to a new field.
Split messages into paragraphs
Since different parts of a text can address different topics or aspects of a topic, it is often a good idea to split texts into smaller chunks prior to the analysis. The most sophisticated way of doing that in Dcipher is through the Segmentation operation, which uses machine learning to measure contextual similarity between adjacent sentences as well as detect references between sentences. In this case we opt for a faster solution by simply splitting the posts into paragraphs using the Split by pattern operation.
Measure text length and remove outliers
To avoid the analysis to be affected by outlier cases in the form of very long paragraphs, we run the Text statistics operation on the paragraphs to measure the number of characters, words, and sentences in the texts. We remove the longest text by selecting them in Document Summary view and applying an exclude filter.
Step 4: Analysis
Most active and influential accounts
Identifying the most active public accounts just requires dragging the authors field to the Group by field drop zone in the Document Summary view. The result is a list of all authors and the number of posts they have posted about Greta Thunberg. Enthusiasm does not necessarily translate into impact, however. To identify the authors that have generated most engagement in relation to Greta Thunberg, we drag the engagement score field to the Apply function drop zone in the Document Summary view and select Average as the function. This calculates the average engagement score for each author. Sorting descendingly, we see that celebrities, such as Rone and Leonardo DiCaprio, as well as media outlets, such as BBC and Breitbart, have had the biggest impact. Greta Thunberg herself is number 8 on the list.
To see what specific authors have posted about Greta Thunberg, we select an author of interest and drag it to the Score by occurrence drop zone of another Document Summary view. This gives us all posts by the selected author (by scoring all rows by the occurrence of that author, hence the name of the drop zone).
Topics in the posts
To get an overview of the topics in the posts, we drag-and-drop the cleaned post field to the Tokenize into bubbles drop zone in the Document Summary view. This splits the posts into words and identifies the parts-of-speech of each word (e.g. nouns and adjectives), which can be used for filtering. The most commonly used words are then presented as bubbles or words in the Bubble view. We can see that prominent words include “activist”, “change”, “strike”, “young”, and “prize”. To get a more nuanced understanding of how these words are used, we drag our new tokens (i.e. words) field to the Display as network drop zone in the Bubble view. After about half a minute of calculating link between words based on how they appear together in posts (or paragraphs, if we use the paragraph field instead of the post field), we get a network showing how words in posts about Greta Thunberg are related to each other. This gives a fast topic overview and reveals, among other things, discussions about rallies and protests in the U.S. and Canada, which Greta Thunberg has taken part in.
To see what has been written about a word of interest, we select the word (hold down the control key to select multiple words) and drag it from the Bubble view to the Document Summary view to score posts based on how much the word appears in them. In this case, we are interested in the word “leader”, and find that Leonardo DiCaprio has posted an Instagram message praising Greta Thunberg as a leader of our time.
The discussion landscape
A powerful capability for exploring the discussion around a topic in Dcipher is document landscaping. We trigger it by dropping our paragraph field in the Document landscaping drop zone in the Scatter view. After a few minutes of processing (the operation is heavy because it requires training a machine learning model from scratch) our 20,000 paragraphs are displayed as dots, where proximity reflects similarity. The axes don’t have any clear meaning; the texts have been projected down to two dimensions in a way that seeks to preserve the higher-dimensional distances between posts. The result is a landscape with dense and less dense regions, where the dense regions reflect topics addressed by many of the texts. To see patterns more clearly, we can switch on the heatmap mode, displaying regions of high and low concentration as hills and valleys.
To explore the landscape we have several options. By hovering over a dot with the cursor, we can read the text it represents. Drag-and-dropping a hill in the landscape to the Document Summary view displays all the documents in that region of the landscape, so that we can read them one by one. Dragging the same hill to the Find overrepresented tokens drop zone in the Bubble view provides a fast way of interpreting the common denominator of the texts in that part of the landscape by calculating and displaying their most characteristic words.
Spending 15 minutes exploring the texts in the different dense regions of the landscape, and examining the words associated with each peak, helps us label each peak and arrive at the landscape image at the beginning of this post.
Get started!
To access our comprehensive social media archive and try out social media mining in Dcipher Analytics, sign up for a free trial. To better understand our social media mining solutions, read more here or check out this guide to social media mining in Dcipher. If you have questions, want to discuss your use case, or get a guided tour, contact us.